Il y a quelque chose de singulier à voir une proposition technique de quelques paragraphes, publiée un mardi de septembre 2024 sur le blog d'un laboratoire de recherche australien, générer autant de bruit dans l'industrie SEO mondiale. Le llms.txt — ce fichier texte qu'on place à la racine d'un site pour orienter les modèles de langage — est devenu en moins de deux ans un sujet de conférence, une ligne de service chez des agences, et l'objet d'une controverse qui dit beaucoup sur la façon dont l'écosystème web traite les nouvelles conventions.
La vraie question n'est pas de savoir si ce fichier est utile. Elle est de savoir pour qui il est utile — et si le débat autour du llms.txt standard adoption ne repose pas, depuis le début, sur un malentendu.
Septembre 2024, l'origine d'une proposition modeste

Le 3 septembre 2024, Jeremy Howard, co-fondateur d'Answer.AI et conférencier à l'université du Queensland et à Stanford, publie la proposition originale publiée sur Answer.AI. Le constat de départ est précis : les fenêtres de contexte des LLM sont trop petites pour ingérer un site entier, et convertir du HTML chargé de navigation, de publicités et de JavaScript en texte lisible par un modèle est un travail difficile et imprécis.
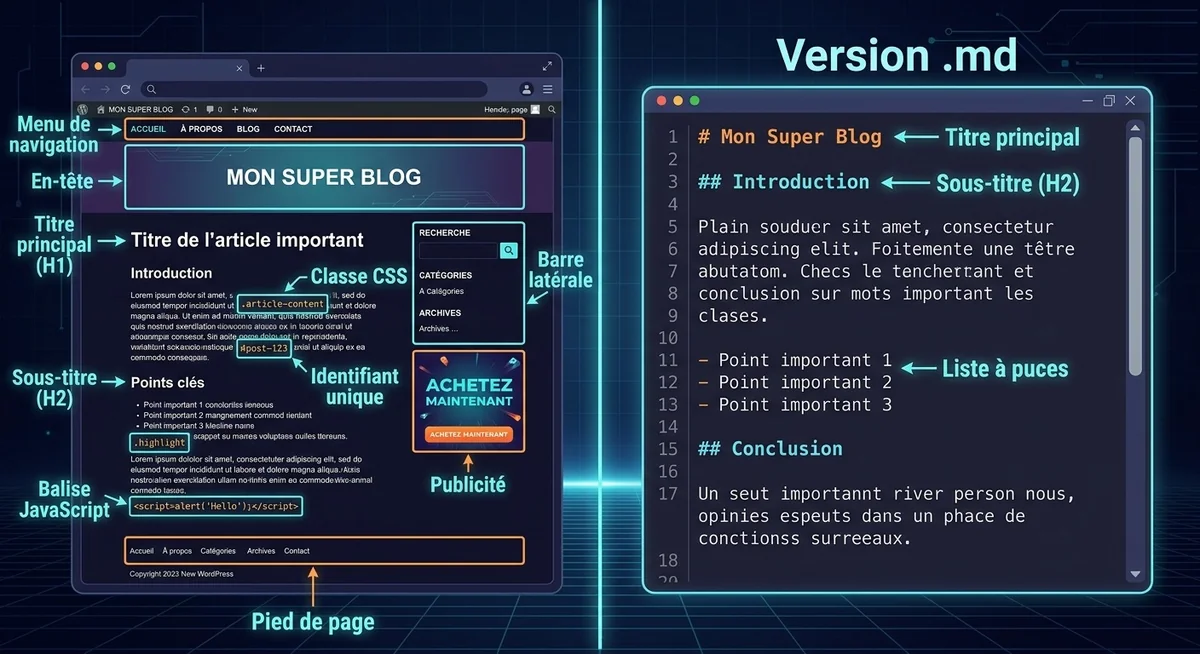
Sa solution : un fichier Markdown placé à /llms.txt, fournissant un résumé de présentation et des liens vers les pages les plus importantes du site. Pas de directive d'exclusion, pas de contrôle d'accès — juste une carte de contenu structurée, lisible par un agent. Le cas d'usage explicite dans la proposition est celui des environnements de développement, où les LLM ont besoin d'accéder rapidement à la documentation de bibliothèques et d'API.
C'est ce détail qui sera massivement ignoré dans les mois suivants.
Ce que l'adoption réelle ressemble en 2026
Les bots qui lisent (vraiment) le fichier
L'adoption du llms.txt a suivi une courbe de diffusion technologique classique : premières adoptes sur des sites techniques, puis propagation vers le SaaS grand public et l'édition au cours du premier trimestre 2026. Une étude de SE Ranking portant sur 300 000 domaines mesure un taux d'adoption d'environ 10 %. Cela semble encourageant jusqu'à ce qu'on regarde les logs de serveur.
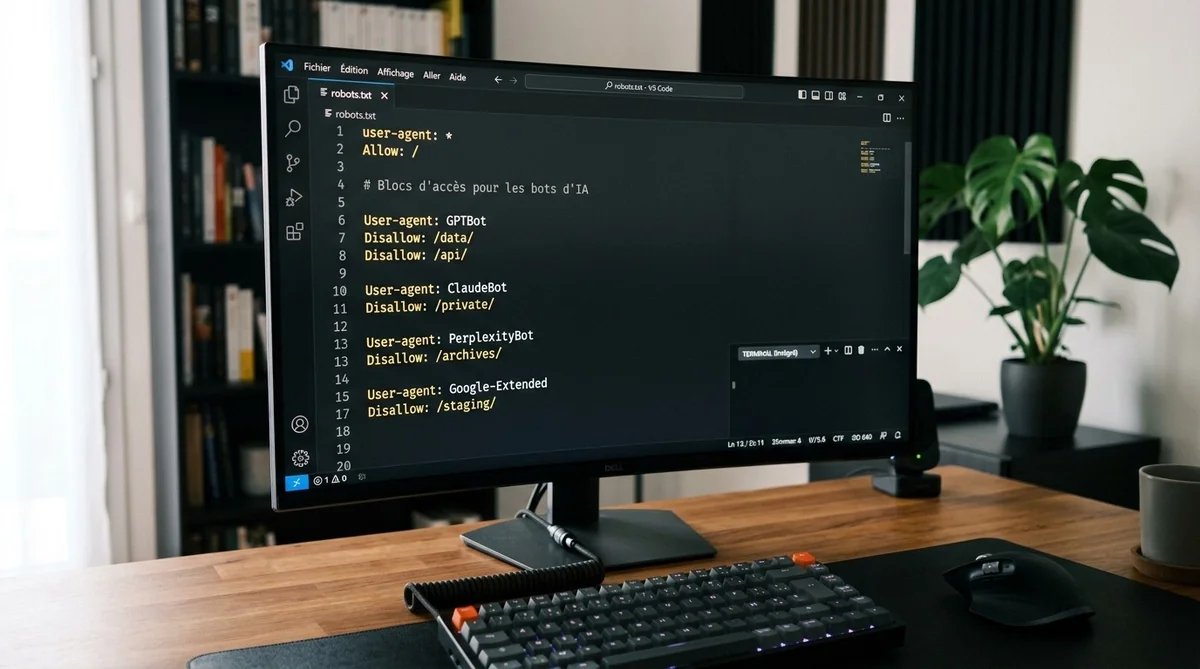
L'analyse de plus de 500 millions d'événements de trafic de bots IA révèle que GPTBot, ClaudeBot, PerplexityBot et Google-Extended ignorent massivement le fichier et parcourent le HTML directement. Sur 90 jours de mesure, une étude indépendante a compté 84 requêtes vers le llms.txt sur 62 100 requêtes de bots IA — soit 0,1 %. Le fichier se comportait moins bien qu'une page de contenu ordinaire sur le même domaine.
John Mueller, de Google, a comparé le llms.txt à la balise meta keywords des années 1990 — une analogie qui n'est pas flatteuse. Google a confirmé ne pas utiliser ce fichier pour l'exploration, l'indexation ou le classement. Aucun grand fournisseur de LLM — OpenAI, Anthropic, Google, Meta, Mistral — n'a officiellement annoncé l'utiliser comme signal dans ses surfaces de réponse en production.
Là où le fichier fonctionne, c'est dans les IDE agentiques. Cursor, Windsurf, Claude Code, GitHub Copilot récupèrent le llms.txt quand on les pointe vers un site de documentation. Les serveurs MCP — comme le mcpdoc open-source de LangChain — consomment directement ces fichiers pour exposer la documentation aux applications hôtes. C'est un usage de développeur, pas un levier de visibilité dans les moteurs génératifs.
Les sites qui l'ont mis en place
Parmi les adoptants notables : Anthropic publie un fichier llms.txt de 8 364 tokens et un llms-full.txt de 481 349 tokens couvrant l'intégralité de sa documentation API. Cloudflare organise le sien par produit — Workers, AI Gateway, Pages, R2 — avec des milliers de lignes permettant à un agent de naviguer dans un écosystème de plus de vingt produits. Stripe structure le fichier par catégories avec une section « Optional » pour les outils secondaires.
Mintlify a joué un rôle d'accélérateur en activant la génération automatique de llms.txt pour tous les sites qu'elle héberge dès novembre 2024 — ce qui a immédiatement équipé des milliers de documentations techniques, dont celles d'Anthropic, Cursor et Windsurf. D'autres noms comme Stripe, Vercel, Pinecone, Zapier, Hugging Face ou Solana ont suivi. Ce sont tous des sites à forte composante développeur.

Pourquoi llms.txt n'est pas — et ne sera pas bientôt — un standard W3C
La spécification reste gérée par la communauté via la spécification de référence sur llmstxt.org, avec des contributions d'Anthropic, de Perplexity et de contributeurs open-source. Un processus de RFC à l'IETF a été discuté, mais rien ne s'est matérialisé à ce jour. Le W3C a ouvert une issue GitHub sur le sujet (issue #506 du dépôt de stratégie) sans donner suite opérationnelle. La situation est celle d'une convention communautaire — pas d'un standard au sens de robots.txt, qui lui bénéficie de la RFC 9309.
Ce statut crée deux problèmes concrets. D'abord, l'absence d'interopérabilité garantie : chaque plateforme interprète les cas limites à sa façon. Les directives comme « disallow » n'ont aucune valeur normative dans ce format. Ensuite, un problème d'adoption dans les secteurs régulés — finance, santé, juridique — où les équipes de conformité ont besoin d'une base textuelle ferme avant d'autoriser la publication.
Le schéma est connu. robots.txt a démarré comme une convention communautaire en 1994 avant de devenir universel. schema.org n'a décollé qu'après l'engagement conjoint de Google, Microsoft, Yahoo et Yandex. Le llms.txt attend encore un engagement comparable de la part des grands opérateurs de LLM. Si Google venait à le soutenir formellement, la dynamique changerait.
Comment construire un bon llms.txt

Le format impose peu de contraintes. La structure recommandée par la spécification originale fonctionne sur trois niveaux :
- Un titre H1 avec le nom du projet ou du site, suivi d'un bloc de citation en Markdown (
>) pour la description — une ou deux phrases qui résument ce que fait le site et à qui il s'adresse. - Des sections H2 thématiques (Documentation, Articles clés, Produits, Optionnel…) contenant chacune une liste de liens annotés au format
[Titre de la page](URL) : description courte. - Une section « Optional » pour les ressources secondaires — celles dont un agent n'a pas besoin sauf requête spécifique.
Quelques règles pratiques qui font la différence :
- Ne pas lister toutes les URL du site — c'est le travail du sitemap.xml. Le llms.txt est une table des matières éditoriale, pas un inventaire exhaustif. Les pages d'archives, de tags, de résultats de recherche interne ou d'URLs paramétrées n'ont pas leur place ici.
- Chaque lien mérite une description d'une ligne qui dit ce qu'on trouve sur la page, pas ce que dit le titre.
- Le fichier doit retourner un HTTP 200, être encodé en UTF-8 et rester accessible sans authentification.
- Synchroniser les URLs avec robots.txt : ne jamais pointer vers des pages bloquées.
Pour observer un exemple concret, le fichier publirank.io/llms.txt illustre cette approche : présentation synthétique en en-tête, sections thématiques bien délimitées, liens annotés sans surcharge. C'est le type de fichier que les agents de développement et les outils MCP peuvent parser sans ambiguïté.
La variante llms-full.txt — adoptée notamment par Anthropic — contient l'intégralité du contenu des pages référencées, dans un seul fichier aplati. Utile pour les agents qui ont besoin d'un contexte complet sans effectuer de requêtes supplémentaires, mais à manier avec précaution : la taille peut vite dépasser les fenêtres de contexte de nombreux modèles.
L'erreur de cadrage qui alimente tout le débat
Jeremy Howard n'a jamais présenté son fichier comme un outil de GEO ou de SEO. Sa proposition adresse l'usage à l'inférence par les outils de codage et les agents IA — pas la visibilité dans les moteurs génératifs. C'est la communauté SEO qui a recodé la proposition en levier de classement, et c'est cette recodification qui explique à la fois l'enthousiasme excessif et les désillusions qui ont suivi.
En mai 2026, avoir un llms.txt ne change pas mesuralement votre probabilité d'être cité par ChatGPT, Claude ou Perplexity dans leurs surfaces de réponse. Les études convergent sur ce point. Mais pour un site dont le public est constitué de développeurs travaillant avec des assistants de codage agentiques, ne pas avoir de llms.txt est un choix qui se voit — Cursor hallucine des endpoints qui n'existent pas, Claude Code génère du code incompatible avec votre API.
C'est la ligne de fracture réelle : infrastructure pour le web agentique d'un côté, signal de visibilité dans les moteurs génératifs de l'autre. Les deux sont des objectifs légitimes, mais ils ne se résolvent pas avec le même fichier.
Pour ceux qui gèrent un site WordPress et veulent intégrer cette couche d'infrastructure sans effort technique supplémentaire, le plugin gratuit Publirank Geo Ready génère automatiquement le llms.txt à partir du contenu existant — articles, pages, catégories. La mise en place est transparente et le fichier reste synchronisé avec les publications. Plus d'informations sur publirank.io.
Questions fréquentes sur le llms.txt standard adoption
Le llms.txt améliore-t-il la visibilité dans ChatGPT ou Perplexity ?
Non, pas de façon mesurable en 2026. Plusieurs études sur des centaines de milliers de domaines ne montrent aucune corrélation entre la présence du fichier et le taux de citation par les moteurs génératifs. GPTBot et PerplexityBot le lisent très rarement selon les logs serveur analysés.
Quelle est la différence entre llms.txt et llms-full.txt ?
Le llms.txt est un index structuré de liens vers le contenu prioritaire. Le llms-full.txt contient le texte complet de toutes les pages référencées dans un seul fichier aplati. Le premier est léger et navigable, le second est pensé pour les agents qui veulent ingérer l'intégralité de la documentation sans requêtes supplémentaires.
Le llms.txt est-il un standard officiel reconnu par le W3C ou l'IETF ?
Non. En mai 2026, il reste une convention communautaire gérée via llmstxt.org. Un processus IETF a été évoqué mais n'a pas abouti. Le W3C a ouvert une discussion sans donner suite concrète. Aucun organisme de normalisation n'a formellement adopté la spécification.
Quels outils génèrent automatiquement un llms.txt ?
Mintlify le génère pour tous les sites de documentation hébergés sur sa plateforme. Yoast SEO propose une option native sous WordPress. Le plugin gratuit Publirank Geo Ready le produit également à partir du contenu existant. Des plugins existent aussi pour Docusaurus, VitePress et Drupal.